書籍の情報が記述されているXML文書の中にある<title>の要素の内容を取り出して、一覧表示するアプリケーションを作成したい場合、どうすればよいでしょうか。
XML文書も実体はテキストファイルであるため、例えばJava言語であれば、テキストファイルを読み書きするクラスを使用して、1行ずつ読み込んでいき、開始タグと終了タグが見つかるまで走査して、要素の内容だけを抜き出すという機能を実装すれば可能です。
ただ、そのような機能をひとつずつプログラミングしていくとすると、それは非常に大変です。例えば、開始タグと終了タグが対応していないなどの、XML文書の文法に誤りがあった場合、その誤りを検出する機能も実装しなければなりません。
XMLの仕様は奥深く、それらを全て満たす機能を自身で実装することがものすごく難しいということは容易に想像できると思います。
そこで登場するのがXMLパーサー(XML parser)です。
XMLパーサー
Javaを含む、各プログラミング言語の開発環境では、XML文書に対する基本的な操作を行うための機能を提供するモジュール(プログラムの部品)が開発されており、そのモジュールをXMLパーサーと呼びます。
XMLパーサーは、XML文書を読み込み、そのXML文書の構造を解析(パース)します。その際、文法エラーがないか(整形式文書となっているか)、DTDもしくはXML Schemaに従っているかどうかの妥当性チェックを行ってくれます。もし、それらに不正があれば、XML パーサーがエラーを通知してくれます。
本カテゴリでは、XMLパーサーを利用してXML文書を操作する方法について見ていきます。
DOMとは
XML パーサーを利用してXML文書を操作するための代表的な方式として、DOM(Document Object Model)とSAX(Simple API for XML)があります。今回は、そのうちのDOMについて見ていきます。
DOMとはXML文書を木構造として解析し、木構造のノードを操作することでXML文書を操作するインターフェースのことです。イメージ図とすると以下のようになります。
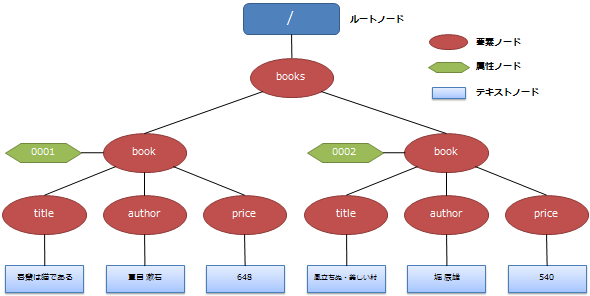
このツリーの1つ1つのノードに直接アクセスし、さまざまな処理を行うコードを記述することで、XML文書を操作します。例えば、DOMを使用して<title>の要素の内容を取り出すには、木構造となっているノードをたどって、該当ノードを探し出します。そして、探し出したノードからデータを取り出す、といった具合です。
ノードからデータを取り出す以外にも、新規ノードを追加したり既存のノードを削除したりすることもできます。